
|
라인 주식회사(LINE Corporation/라인, 대표이사 사장: 이데자와 다케시/ Idezawa Takeshi)가 세계 최대 규모의 음성·음향·신호처리 학술대회인 ICASSP 2023에서 논문 8편이 채택됐다고 밝혔다.
어떤 논문인데
채택논문은 다음과 같다. 이중 7번과 8번은 각각 도쿄도립대학, 와세다대학과의 공저 논문이다.
1. R. Yamamoto et al., “NNSVS: NEURAL NETWORK BASED SINGING VOICE SYNTHESIS TOOLKIT”
2. R. Yoneyama et al., “Non-parallel High-Quality Audio Super Resolution with Domain Adaptation and Resampling CycleGANs”
3. M. Kawamura et al., “FAST AND HIGH-FIDELITY END-TO-END TEXT-TO-SPEECH FOR EDGE DEVICES WITH MULTI-BAND GENERATION AND INVERSE SHORT-TIME FOURIER TRANSFORM”
4. Y. Shirahata et al., “Period VITS: Variational inference with explicit pitch modeling for End-to-End emotional speech synthesis”
6. Y. Fujita et al., “Neural Diarization with Non-autoregressive Intermediate Attractors”
7. T. Kawamura et al., “Effectiveness of Inter- and Intra-Subarray Spatial Features for Acoustic Scene Classification”
8. H. Zhao, et al., “Conversation-oriented ASR with multi-look-ahead CBS architecture”
올해로 48회차를 맞이하는 ICASSP(International Conference on Acoustics, Speech, and Signal Processing)는 국제전기전자협회 신호처리학회(IEEE Signal Processing Society)가 주최하는 음성·음향·신호처리 분야 내 세계 최대 규모의 국제학회다.
라인이 주저자인 논문 수는 지난해 3편에서 두 배 늘어나는 성과를 거두었다. 모두 학회 개최 기간인 6월 4일부터 10일 중 발표된다.
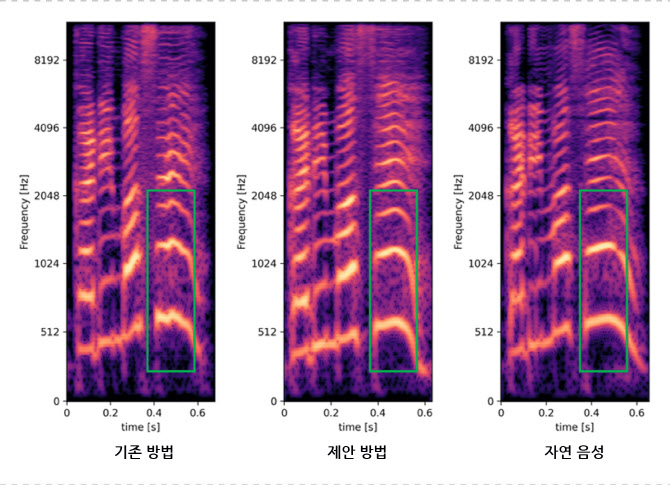
자연스러운 음성 합성을 실현하는 제안에 높은 평가
이번 ICASSP 2023에서 채택된 논문에는 감정 음성 합성 시 텍스트에서 음성 파형으로 변환하는 과정에서 음성 피치 정보(음성 높이)를 이용하는 엔드투엔드(End-to-End) 모델에 관한 제안이 소개됐다.
제안 방법에서는 감정 음성 합성 시 보다 중요한 피치 정보를 양(陽)으로 모델링했다.
이를 통해 생성 음성의 피치 정보를 보다 정확하게 표현할 수 있게 되어, 기존 방법으로는 생성이 어려웠던 피치가 극단적으로 높거나 낮은 발화에서도 보다 자연스럽고 안정된 결과를 얻을 수 있음을 입증했다.
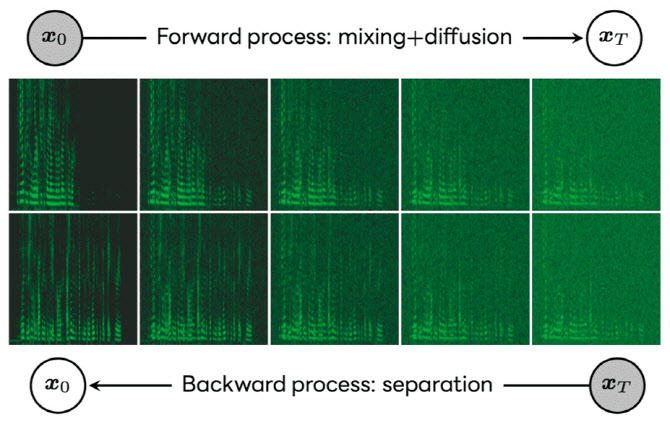
다수의 화자가 혼재된 음성을 분리하는 음원 분리 시 이미지 생성에도 활용되는 확산 모델을 이용하는 방식이 채택됐다.
머신러닝을 이용하는 기존의 음원 분리는 교사 데이터의 음성 분리도를 극대화하는 식별 모델을 이용하는 방식이 주류였으나, 분리도가 높은 음성이라도 인간이 듣기에는 부자연스러운 경우가 종종 있었다.
제안 방법에서는 이미지 생성에도 활용되는 생성 모델 중 하나인 확산 모델을 음원 분리에 활용함으로써 자연스러운 음성 생성을 실현했다. 확산 모델을 활용한 결과, 분리음의 왜곡이 줄어들어 인간의 지각 능력에 기반한 음성 품질 평가 지표(DNSMOS)에서 기존 방법을 상회했다.
|






![[포토]한덕수 대통령 권한대행 국무총리 탄핵소추안 투표하는 우원식 국회의장](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700978t.jpg)
![[포토] 달러 상승 이어져...](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700871t.jpg)
![[포토] 헌법재판소 소심판정](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700760t.jpg)
![[포토] 정청래 단장과 김이수 전 헌법재판관](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700742t.jpg)
![[포토] 윤석열 법률대리인 헌재 출석](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700731t.jpg)
![[포토]내수경기활성화 민당정협의회 열려](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700609t.jpg)
![[포토]입장하는 이재명 대표](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700546t.jpg)
![[포토] 달려라~](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700515t.jpg)
![[포토]이재명 "한덕수·국민의힘 내란 비호세력 탄핵 방해로 민생 경제 추락"](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122700363t.jpg)
![[포토]윤이나,후배 양성을 위해 2억원 기부했어요](https://spnimage.edaily.co.kr/images/vision/files/NP/S/2024/12/PS24122600088h.jpg)
![45년간 자리 지킨 ‘포프모빌’…전기차로 바뀌었다는데[누구차]](https://image.edaily.co.kr/images/vision/files/NP/S/2024/12/PS24122800166h.jpg)


![한강뷰 보며 케이터링 즐긴다…호텔 같은 ‘이 회사’[복지좋소]](https://image.edaily.co.kr/images/vision/files/NP/S/2024/12/PS24122800051h.jpg)